IPFS : l'hébergement de données en pair-à-pair

Décentraliser la distribution de données
L’hébergement de données est aujourd’hui au cœur des infrastructures numériques. Celles-ci sont généralement stockées sur des serveurs informatiques gérés par des organisations ou des prestataires spécialisés. Un gestionnaire de données doit se donner les moyens de les distribuer, de maintenir ses infrastructures et d’assurer leur sécurité. Ces serveurs constituent des points de défaillance ; s’ils ne fonctionnent plus, les données ne sont plus disponibles.
IPFS (InterPlanetary File System) est un protocole de d’hébergement décentralisé de données. Son rôle est de connecter un ensemble de serveurs indépendants les uns des autres, pour qu’ils se partagent des fichiers sans dépendre d’un serveur central. Le protocole a été créé en 2015 par Juan Benet, et c’est une technologie de référence du web décentralisé (dWeb).
Présentation
Sur le web traditionnel, lorsque vous souhaitez accéder à une ressource, vous allez utiliser une URL (Uniform Resource Locator) pour la localiser. Prenons l’exemple de du white paper de Bitcoin, hebergé sur de site Web bitcoin.org :
https://bitcoin.org/bitcoin.pdf
Cette URL est composée de plusieurs informations :
- https:// : c’est le protocole à utiliser pour accéder à la ressource. Il s’agit, dans cet exemple, du protocole HTTP combiné à un certificat TLS ou SSL, délivré par une autorité de certification.
- bitcoin.org : c’est le nom de domaine permettant de connaître l’adresse du serveur web où se situe le Web. Il est résolu grâce au système de nom de domaine (DNS), qui permet d’obtenir l’adresse IP du serveur.
- /bitcoin.pdf : c’est le chemin pour accéder à la ressource disponible sur le serveur. Ici, en l’occurence, il s’agit du nom du fichier.
En entrant cette URL dans votre navigateur web, vous allez accéder à la page web qui est hébergée sur un serveur, situé quelque part sur la planète.
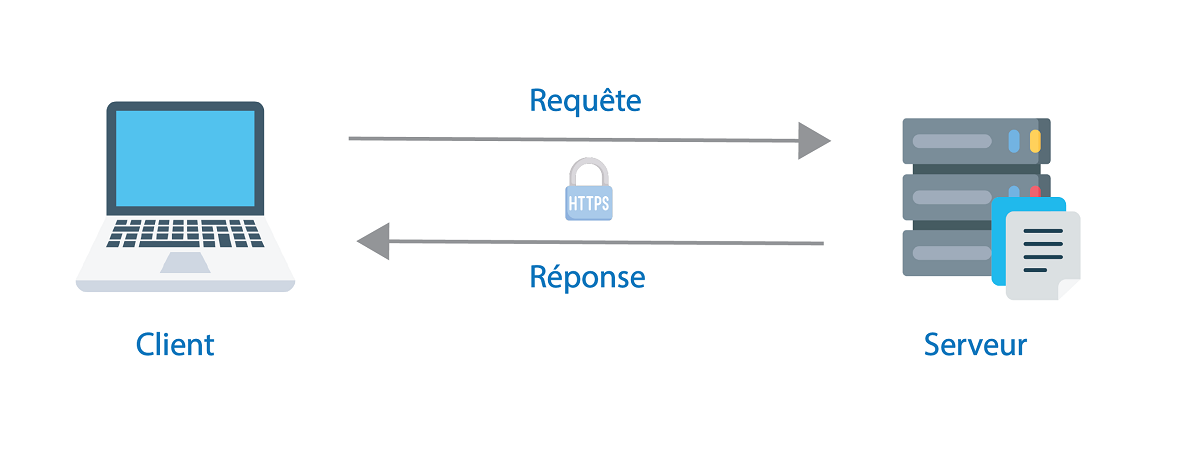
Cet échange est basé sur un modèle client-serveur :
- Le client (le navigateur web) envoie une requête à un serveur web.
- Le serveur reçoit les requêtes et répond avec la ressource demandée. La transaction se fait à travers le protocole HTTPS.
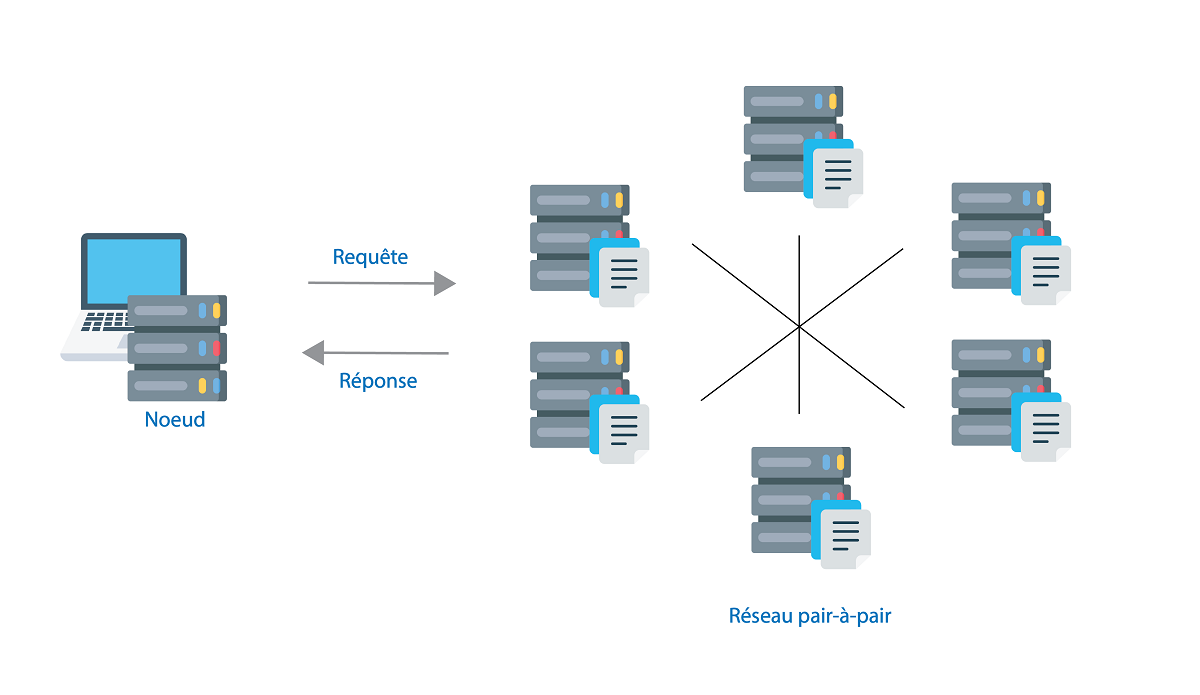
IPFS permet d’héberger n’importe quels types de données de manière décentralisée. Elles ne sont pas distribuées par un seul serveur, mais par plusieurs nœuds du réseau, indépendants les uns des autres.
Le système est basé sur une architecture pair-à-pair (P2P), sur laquelle chaque nœud joue le rôle de client et de serveur ; chaque nœud peut accéder et distribuer des données. Le protocole d’échange est donc un équivalent du protocole HTTP, mais avec un paradigme différent.
Pour accéder à une ressource sur IPFS, le protocole ne se base pas sur sa localisation, mais sur son contenu. Chaque ressource est représentée par un identifiant unique, défini par son contenu (CID ou Content Identifier). Reprenons l’exemple précédent ; le white paper de Bitcoin est hébergé sur IPFS. Il est identifié de cette façon :
QmRA3NWM82ZGynMbYzAgYTSXCVM14Wx1RZ8fKP42G6gjgj
Pour accéder au fichier, il faut passer par un nœud connecté au réseau IPFS. Si vous n’avez pas de nœud IPFS sur votre ordinateur, il est possible d’utiliser une extension de navigateur ou un service web qui permet d’interroger un nœud mis à disposition par quelqu’un d’autre. C’est ce qu’on appelle une passerelle. Par exemple, vous pouvez utiliser celles mises à disposition par IPFS, Cloudflare ou encore Infura.
https://ipfs.io/ipfs/QmRA3NWM82ZGynMbYzAgYTSXCVM14Wx1RZ8fKP42G6gjgj
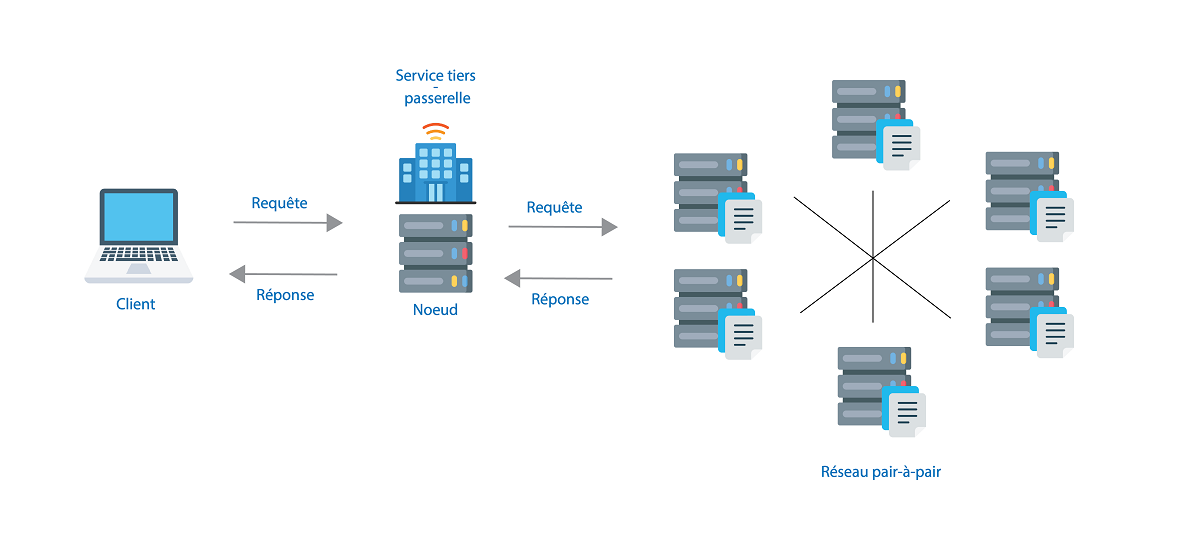
Pour interagir avec IPFS, il est donc possible d’utiliser des passerelles, mais aussi des logiciels, extensions de navigateurs et d’autres outils dédiés (CLI, API, etc.). Notez qu’il est aussi possible d’utiliser IPFS sur un réseau local et privé.
La décentralisation des données apporte plusieurs propriétés :
- Disponibilité : les données étant présentes sur plusieurs nœuds, leur disponibilité est accrue.
- Liberté : n’importe qui peut utiliser IPFS et partager les données qu’il souhaite. Les données sont dupliquées sur plusieurs nœuds indépendants, ce qui rend la censure plus compliquée.
- Performance : les ressources sont accessibles en pair-à-pair. De ce fait, il n’y a pas besoin d’aller chercher un fichier sur un serveur situé à des milliers de kilomètres si votre voisin l’a déjà. Cela rend donc l’accès aux données plus efficace.
Principe
IPFS est un système collaboratif et participatif, sur lequel chaque fichier est représenté par un identifiant unique. Si personne ne connaît l’identifiant d’un document, personne ne pourra y accéder. D’un autre côté, un document ne peut pas être supprimé d’IPFS s’il y a au moins un nœud du réseau qui le rend disponible.
Cela est similaire au web traditionnel ; il est impossible de supprimer un fichier qui a été copié sur plusieurs sites web. La différence sur IPFS, c’est que vous pouvez trouver les copies à l’aide de l’identifiant unique, si celles-ci n’ont pas été modifiées entre temps.
IPFS fonctionne si les utilisateurs téléchargent et partagent les fichiers sur le réseau. Par défaut, lorsqu’un utilisateur accède à un fichier sur IPFS, celui-ci est automatiquement partagé, de manière à le rendre disponible aux autres pendant un temps limité. Il est aussi possible de distribuer des fichiers de manière permanente ; c’est la notion de pin / unpin (épingler / désépingler). Si vous connaissez le téléchargement par torrent, c’est le même principe.
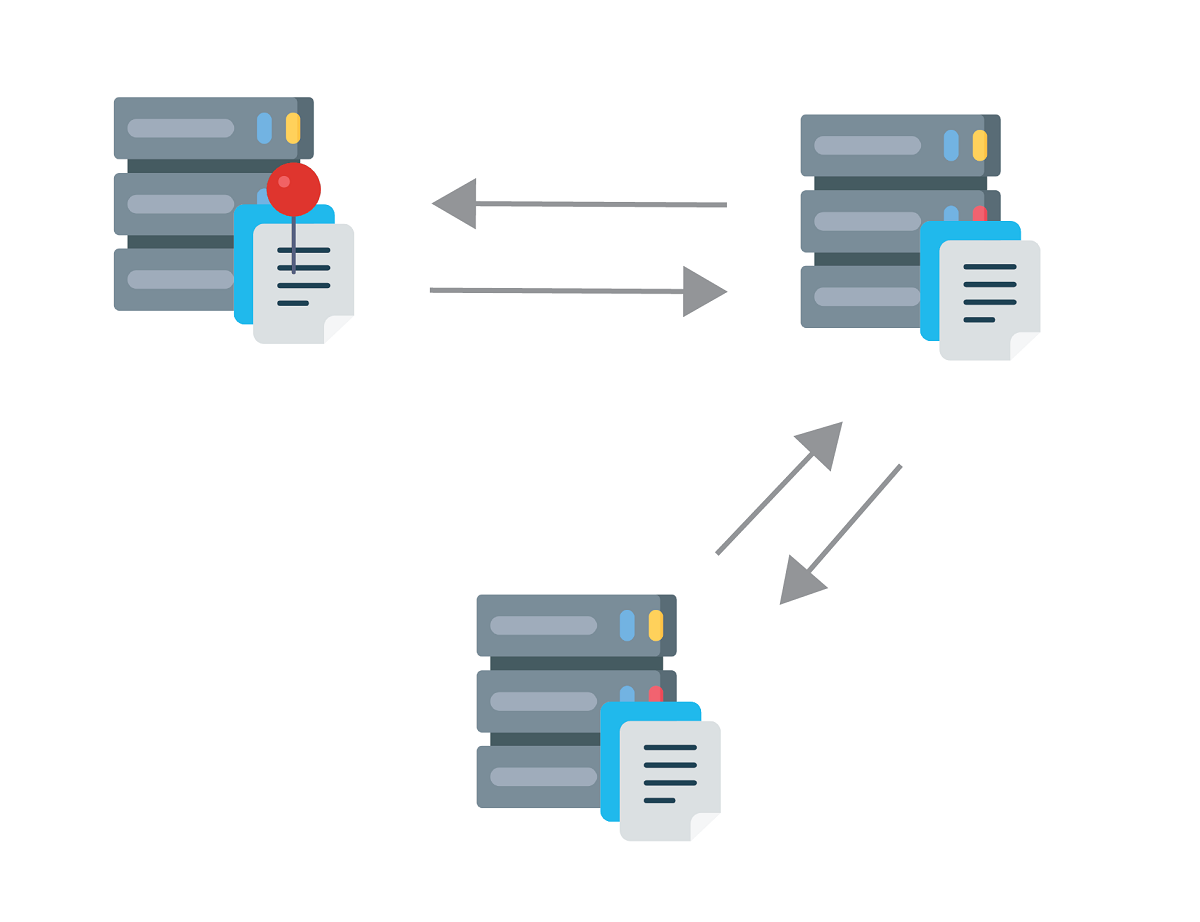
Pour héberger des fichiers, vous devez alors les pin sur IPFS pour être certain qu’ils soient toujours accessibles. Pour cela, soit il faut utiliser un nœud toujours connecté au réseau, soit utiliser des services appelés pinning services, qui le feront à votre place (de la même manière que les hébergeurs traditionnels). Ce mode de fonctionnement pousse à la collaboration. Vous pouvez, entre amis ou partenaires, rendre disponibles vos données.
Cas d’usage
De par les propriétés qu’apporte le pair-à-pair, IPFS peut être utile pour différents cas d’utilisation.
Il permet le stockage de grande quantité de données, répartie entre différents nœuds. Cela peut être des sites web, des archives ou tout type de données. La réplication sur différents clusters permet de partager des documents avec de bonnes performances en termes de débit. L’aspect décentralisé permet rend le partage de données difficilement censurable. Lorsqu’un contenu est distribué, il est ensuite partagé par tous les nœuds qui y accèdent. Cela apporte de la liberté et de l’indépendance aux créateurs de contenu.
L’identifiant d’un fichier peut être inscrit sur une Blockchain. Une Blockchain est un registre de données décentralisé, sur lequel les informations inscrites sont horodatées et immuables ; elles ne peuvent pas être modifiées ou supprimées. De ce fait, cela permet d’horodater un document et prouver qu’il a existé à un instant t.
Il est aussi possible de configurer un identifiant IPFS derrière un nom de domaine, notamment un nom ENS (Ethereum Name Service). Par exemple, nous avons configuré notre site web derrière le nom cryptoms.eth. Ce principe permet d’avoir un nom de domaine et un site web décentralisés ; c’est ce qu’on appelle le dWeb. Pour accéder au dWeb, vous pouvez utiliser un navigateur web compatible, ou utiliser une passerelle comme eth.link. Le moteur de recherche Almonit permet notamment d’explorer différents sites Web déployés avec ENS et IPFS. Notez aussi que le navigateur Web Brave supporte nativement IPFS.
Voici quelques exemples de projets qui utilisent IPFS :
- PeerPad : une solution d’édition de document collaborative
- DTube : une plateforme vidéo
- Audius : une plateforme de musique
- IPVC : un gestionnaire de version (comme Git) décentralisé
- OrbitDB : une base de données distribuée
- Fleek : un service de déploiement de sites web
- FileCoin : système coopératif de stockage numérique basée sur une Blockchain
- Microsoft ION : le projet d’identité numérique de Microsoft
Comment ça fonctionne ?
IPFS est un système est basé sur trois grands principes :
- L’adressage des contenus
- La représentation des contenus
- La découverte des contenus
Adressage de contenu
Le protocole se base sur un système d’adressage pour identifier des fichiers. Chaque fichier est identifié par une empreinte cryptographique unique, appelée content identifier (CID). Cette empreinte est calculée à l’aide d’une fonction de hachage à partir des données contenues dans le fichier. Ce principe est souvent utilisé pour obtenir une signature numérique d’un fichier ou une somme de contrôle (checksum) ; cela permet de vérifier l’intégrité d’un fichier.
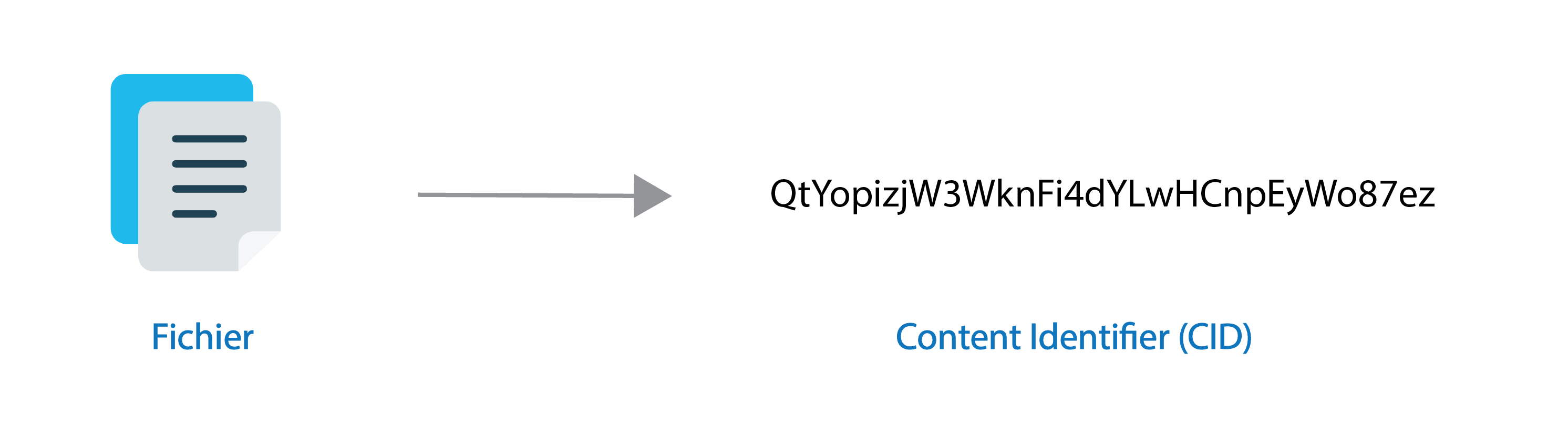
Pour permettre l’adressage de tous types de données sur le réseau, IPFS utilise IPLD (InterPlanetary Linked Data). C’est un outil qui permet d’obtenir un identifiant unique en fonction du type de structure de données.
Un identifiant comme “QmRA3NWM82ZGynMbYzAgYTSXCVM14Wx1RZ8fKP42G6gjgj” est donc unique et correspond au contenu du white papier de Bitcoin. Si cette page est modifiée, un autre identifiant devra être utilisé pour accéder à la nouvelle version de celle-ci. IPFS propose des solutions pour justement permettre aux utilisateurs d’accéder toujours à la dernière version d’un fichier : IPNS.
L’idée d’IPNS (InterPlanetery Name System) est de pouvoir créer des identifiants qui pointent vers la dernière version d’un fichier.
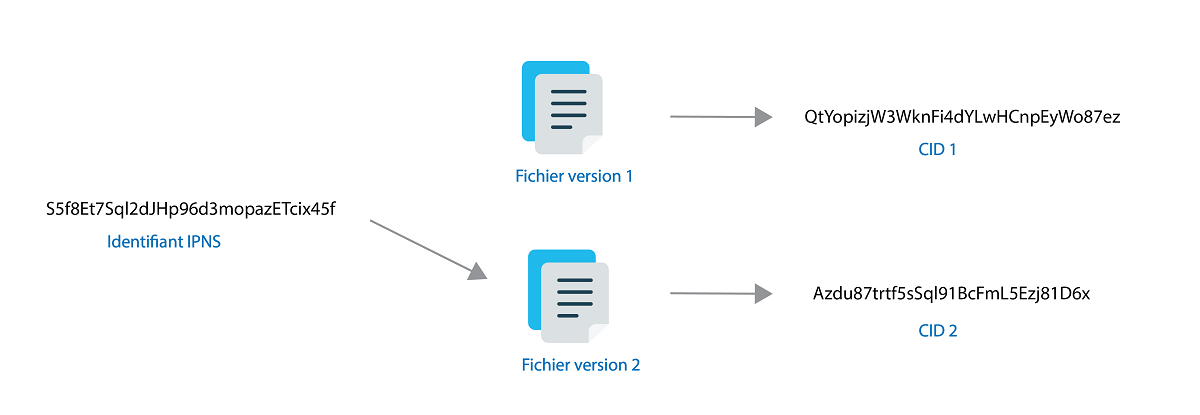
Cependant, les identifiants restent des empreintes cryptographiques difficilement lisibles, et impossibles à retenir. Pour faciliter leur utilisation, il est possible de les configurer derrière un nom de domaine.
Représentation des contenus
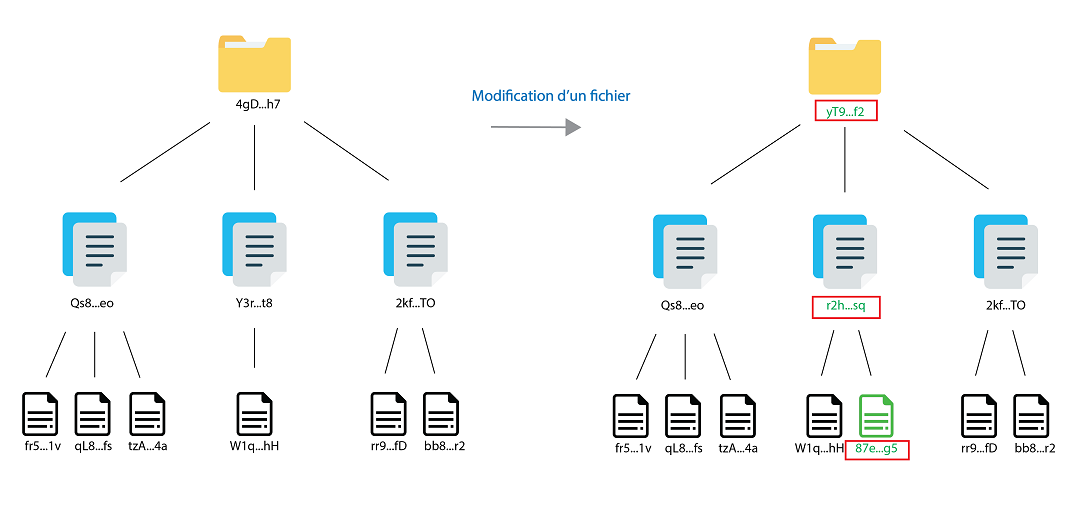
IPFS utilise une structure de données basée sur des graphes orientés acycliques (DAG), plus précisément des arbres de hachage (arbres de Merkel). Ce concept est particulièrement utilisé dans les systèmes distribués, notamment les protocoles Blockchain.
Un arbre de Merkel est une structure qui contient des empreintes cryptographiques d’un volume de données. Le principe est de pouvoir vérifier l’intégrité d’un ensemble de données sans avoir besoin de les vérifier une par une.
IPFS utilise ce concept pour identifier les fichiers et les répertoires. Si un fichier contenu dans un répertoire est modifié, l’empreinte (donc l’identifiant) de celui-ci ainsi que celle du répertoire changent. Cela permet de détecter efficacement où il y a eu une modification, et aux utilisateurs de retélécharger seulement le fichier modifié. Cela améliore ainsi les performances lors des téléchargements. De plus, chaque fichier est divisé en plusieurs blocs de données. Cela permet de télécharger un fichier à partir de plusieurs sources en même temps.
Réseau p2p
Découverte des noeuds
Lorsqu’un nœud IPFS démarre, il va chercher à se connecter à d’autres nœuds du réseau via un protocole de découverte de nœuds.
Ce protocole est basé sur Kademlia, aussi utilisé par d’autres systèmes P2P (eMule, Bittorrent, Ethereum, Bitcoin, etc.). Il s’appuie sur le principe des tables de hash distribuées ou DHT. IPFS utilise notamment la librairie libP2P pour gérer ce mécanisme.
Chaque nœud a un identifiant unique ainsi qu’une adresse, et dispose d’une table de clés/valeurs avec les identifiants et adresses des nœuds qu’il connaît. Au démarrage, un nœud va se connecter à des nœuds prédéfinis, et leur demander les informations sur les nœuds qu’ils connaissent. Ainsi, il va se connecter à plusieurs d’entre eux.
Découverte de contenu
Le processus pour télécharger un fichier sur IPFS se déroule en 3 phases :
- Découverte
Pour récupérer un contenu, IPFS utilise aussi une table de hachage distribuée. Cette table associe des identifiants de contenu (CID) avec les identifiants des nœuds qui les hébergent. Lorsqu’un nœud veut accéder à un contenu, il récupère donc les identifiants des nœuds sur lesquels le contenu est présent.
- Routage
Ensuite, il va utiliser la table qui contient les adresses des noeuds pour s’y connecter.
- Échange
Une fois connecté, le nœud va télécharger le contenu à partir des paires identifiées. Pour cela, IPFS utilise le module Bitswap. Les différentes parties du fichier demandé peuvent être téléchargées à partir de sources différentes, comme lors de téléchargement de torrent ; cela améliore la rapidité de téléchargement. Une fois le contenu téléchargé, son intégrité est vérifiée : l’empreinte cryptographique est calculée et comparée avec l’identifiant du fichier demandé.
Un pas de plus pour le web décentralisé
IPFS propose donc une solution d’hébergement de données décentralisée, performante et open source. En s’appuyant sur des technologies pair-à-pair, les données peuvent être distribuées sur le réseau IPFS et bénéficier de plus de résilience.
L’identification de fichiers basée sur leur contenu permet une approche différente de l’adressage. Celle-ci à l’avantage de permettre à n’importe qui disposant d’un identifiant, d’accéder à la ressource correspondante à partir du moment où elle est hébergée par au moins un nœud. Ce fonctionnement pousse à la participation et la collaboration des utilisateurs.
Le projet IPFS est soutenu par un certain nombre d’acteurs, et dispose d’un écosystème grandissant. Plusieurs applications se construisent en exploitant ce protocole, notamment des applications sur Blockchain (dApps), des plateformes d’hébergement de données ou encore de streaming audio/vidéo. IPFS s’inscrit comme un protocole de référence dans les technologies du web décentralisé (dWeb).
De notre côté, nous avons hébergé notre site web sur IPFS. Celui-ci est disponible ici : cryptoms.eth (ENS).
